Table of contents
1
Table of contents
2
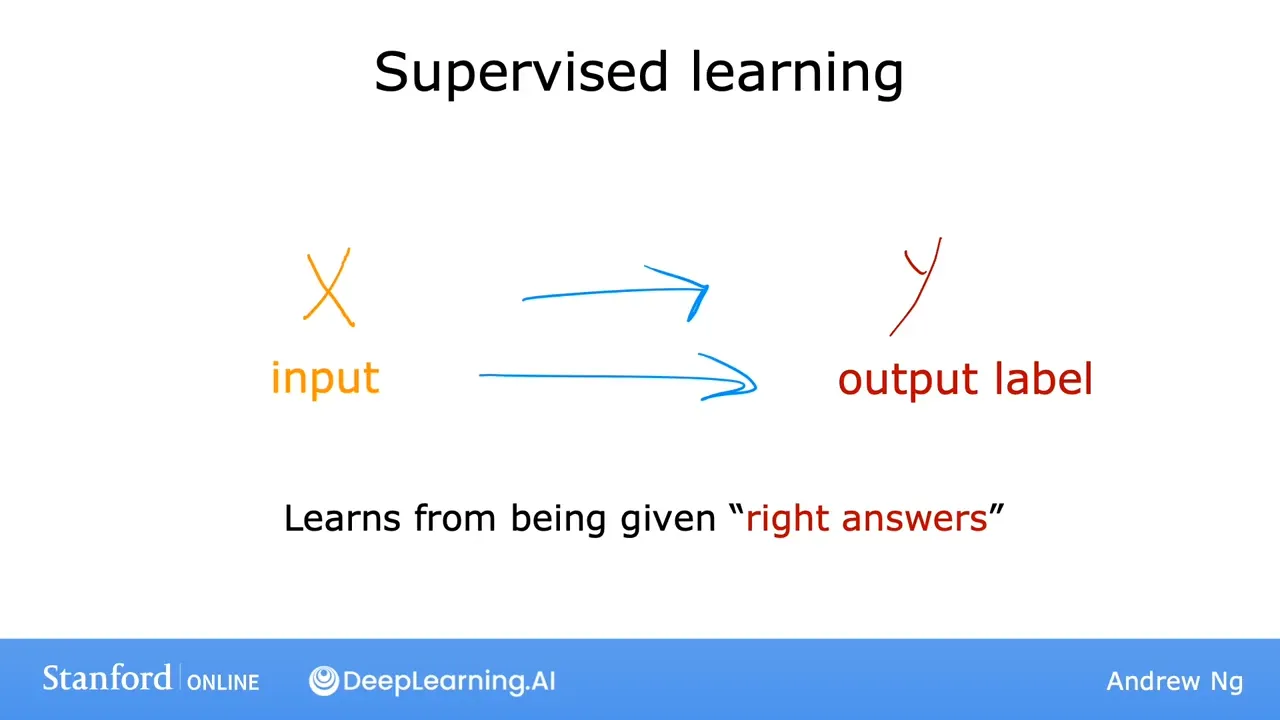
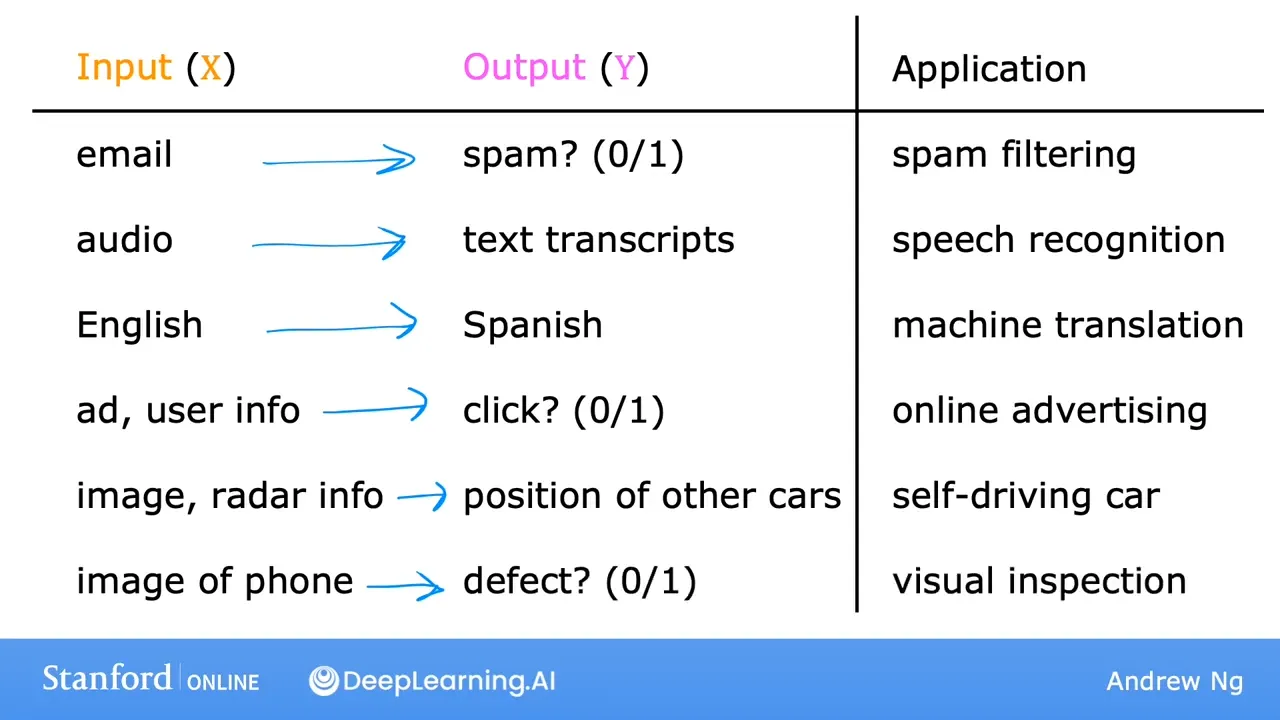
监督学习的基本要点
3
分类问题概述(预测离散值/类别标签)
4
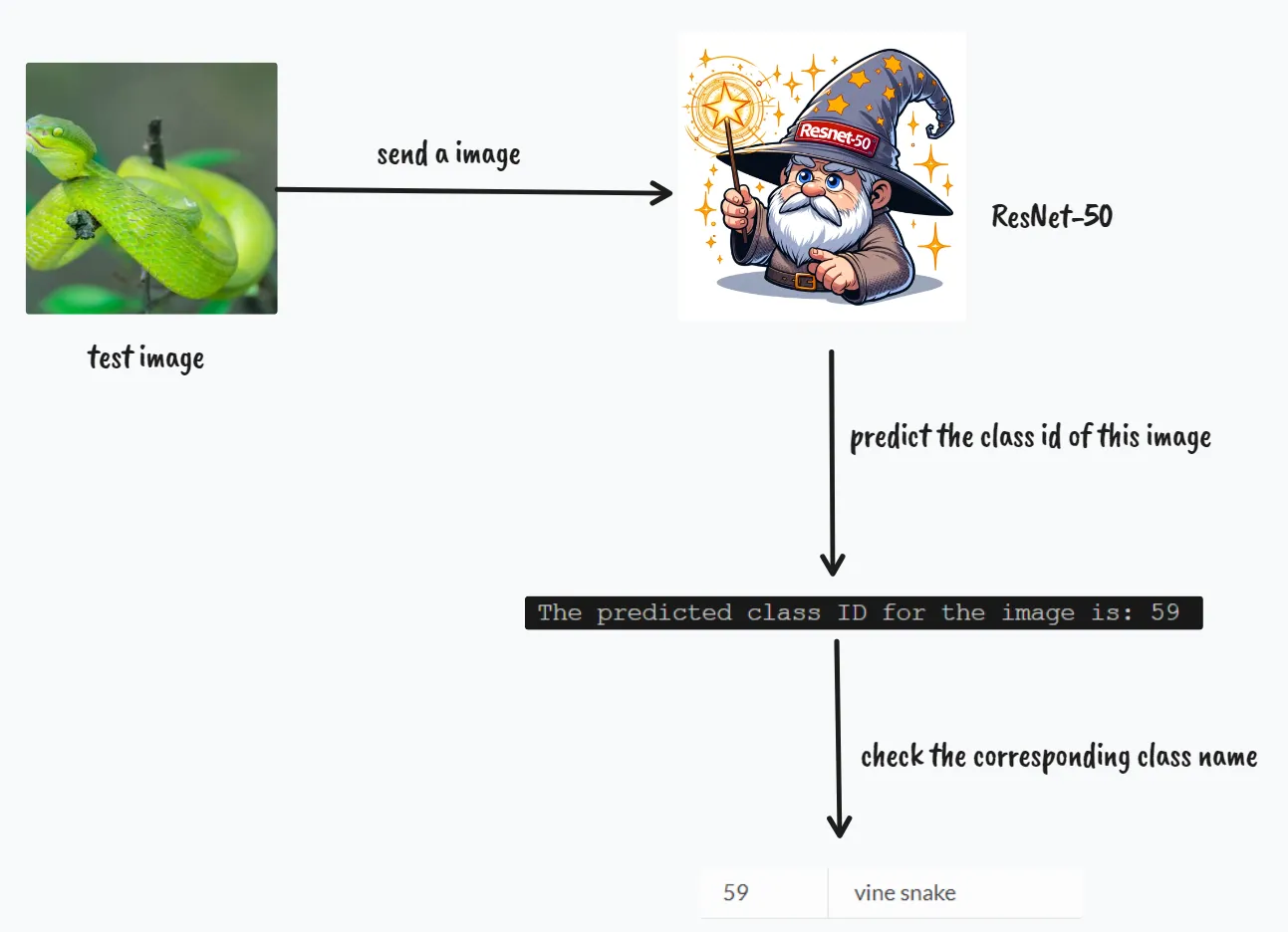
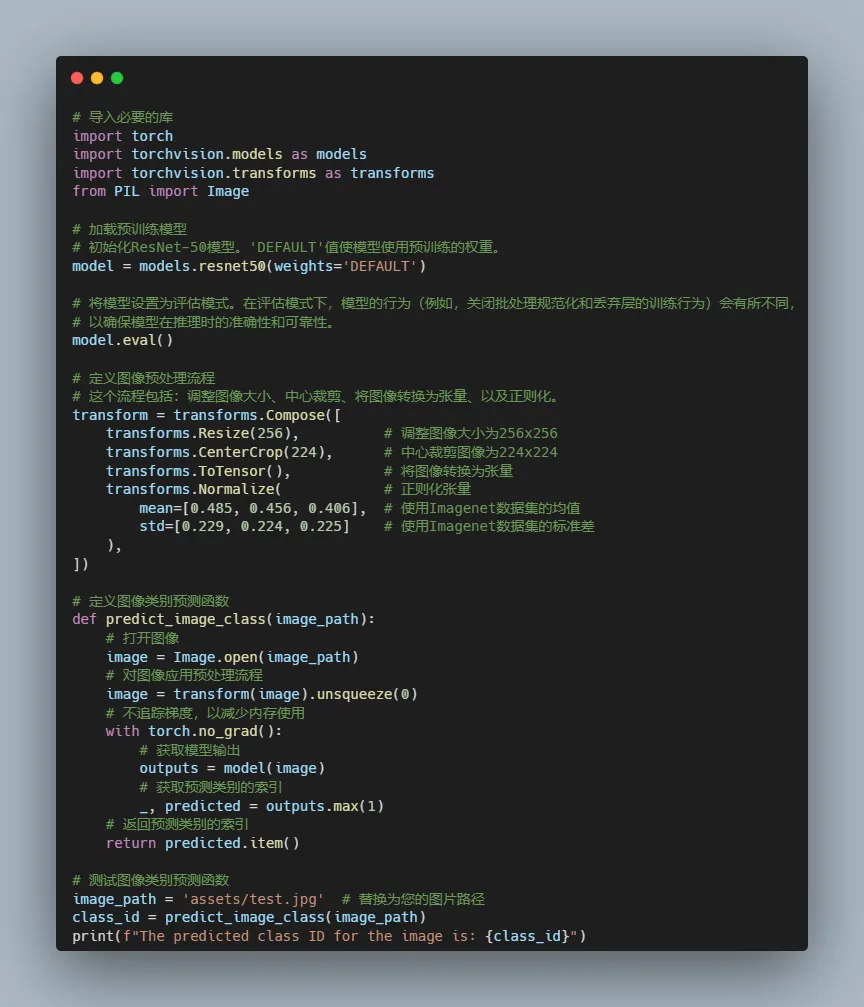
分类问题的应用
- 使用预训练的ResNet-50模型(基于ImageNet数据集的子集训练得到)进行图片分类。
5
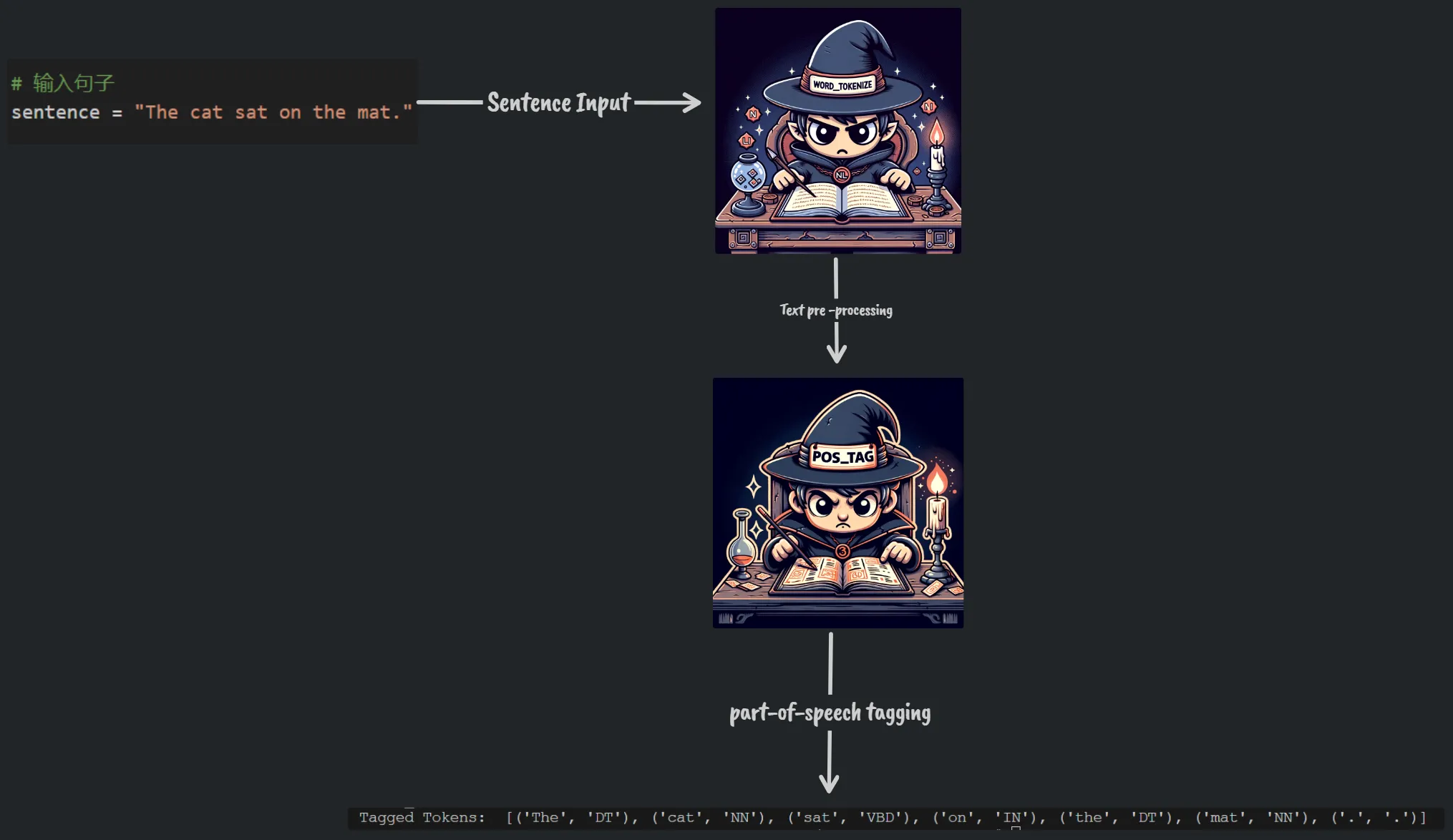
标注问题(分类问题的扩展,预测离散值/类别标签)
6
标注问题(分类问题的推广)的应用
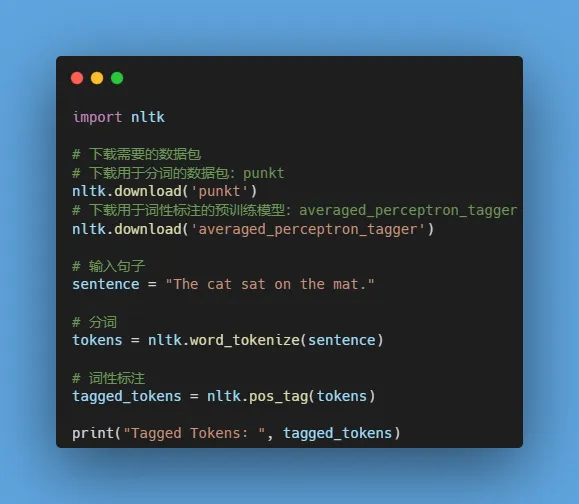
- 使用NLTK库的预训练模型—平均感知机标注器(averaged_perceptron_tagger)和词性标签集—(Penn Treebank),对英文句子进行词性标注。
7
回归问题(预测连续值)
8
回归问题的应用
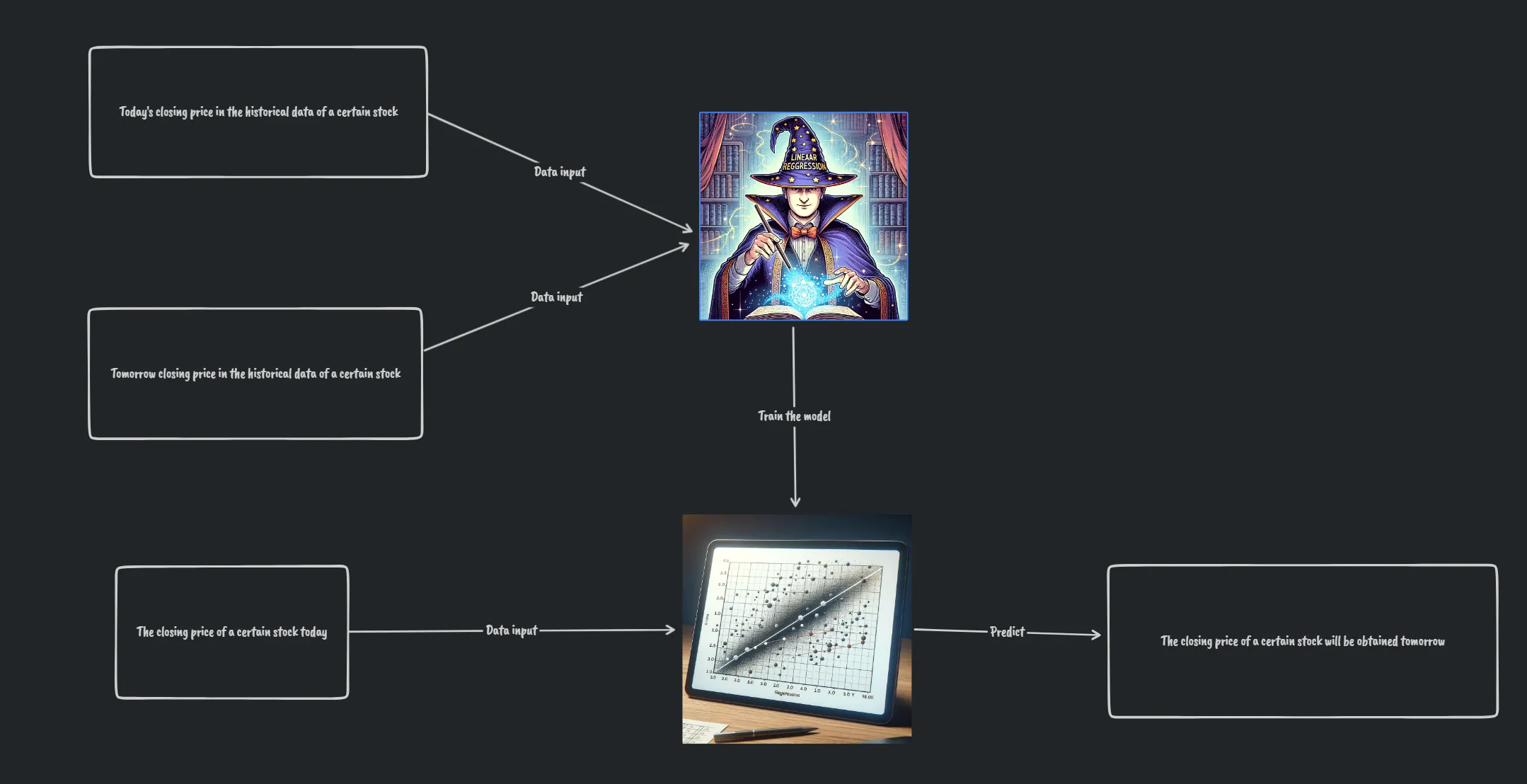
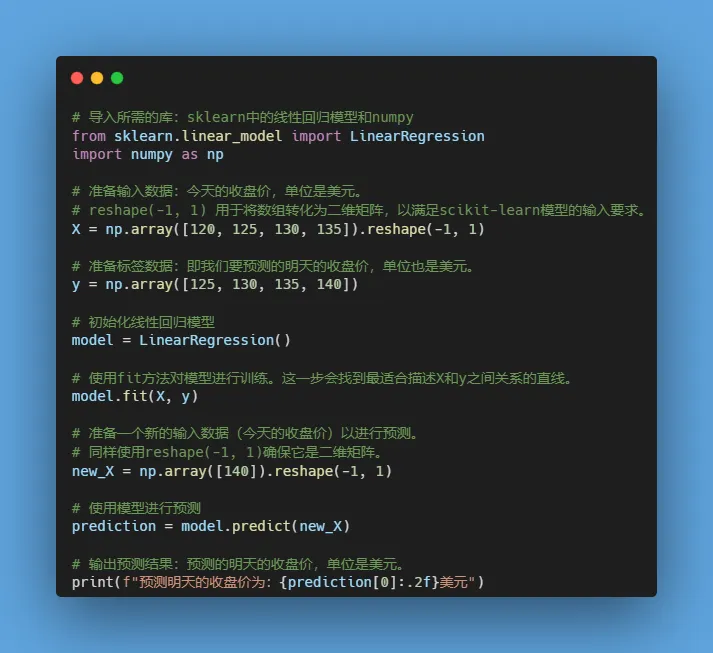
- 使用LinearRegression模型,基于NumPy库进行数据准备和模型训练,用于预测股票的明天收盘价。
9
监督学习在大语言模型中的应用
ChatGPT的模型微调过程利用到了基于人类反馈的强化学习(RLHF),基于人类反馈的强化学习可看作是结合了监督学习和强化学习的方法。via

今年9月份,OpenAI新出的GPT-4V,能看,能听,能说。其中的听,使用的是OpenAI自己研发的whisper模型,其中利用到了监督学习。via

研究生小组前段时间使用国内清华大学开源的ChatGLM2-6B大语言模型,附加自己的数据集(train.json和dev.json)对基础大模型进行微调时,用到了监督学习。
上周OpenAI首届开发者大会后,推出的Create a GPT功能,允许用户用多轮对话的形式创造出特定领域的GPT,这种多轮对话形式的模型微调,技术中也涉及监督学习的身影。

10
总结
监督学习应用多样,分类和回归问题方面的应用还有很多。
除了分类和回归这两大监督学习的基本问题外,随着技术的进步,可能会出现新的抽象或特定的应用场景,这些场景可能不完全符合传统的分类和回归框架,但它们的核心仍然是基于带标签的数据进行模型训练。
监督学习配合其他机器学习分支,为当下大热的大语言模型助力。
11
Thank you for listening!
12